
Nvidia and Tesla Partner on AI Supercomputing





Introduction
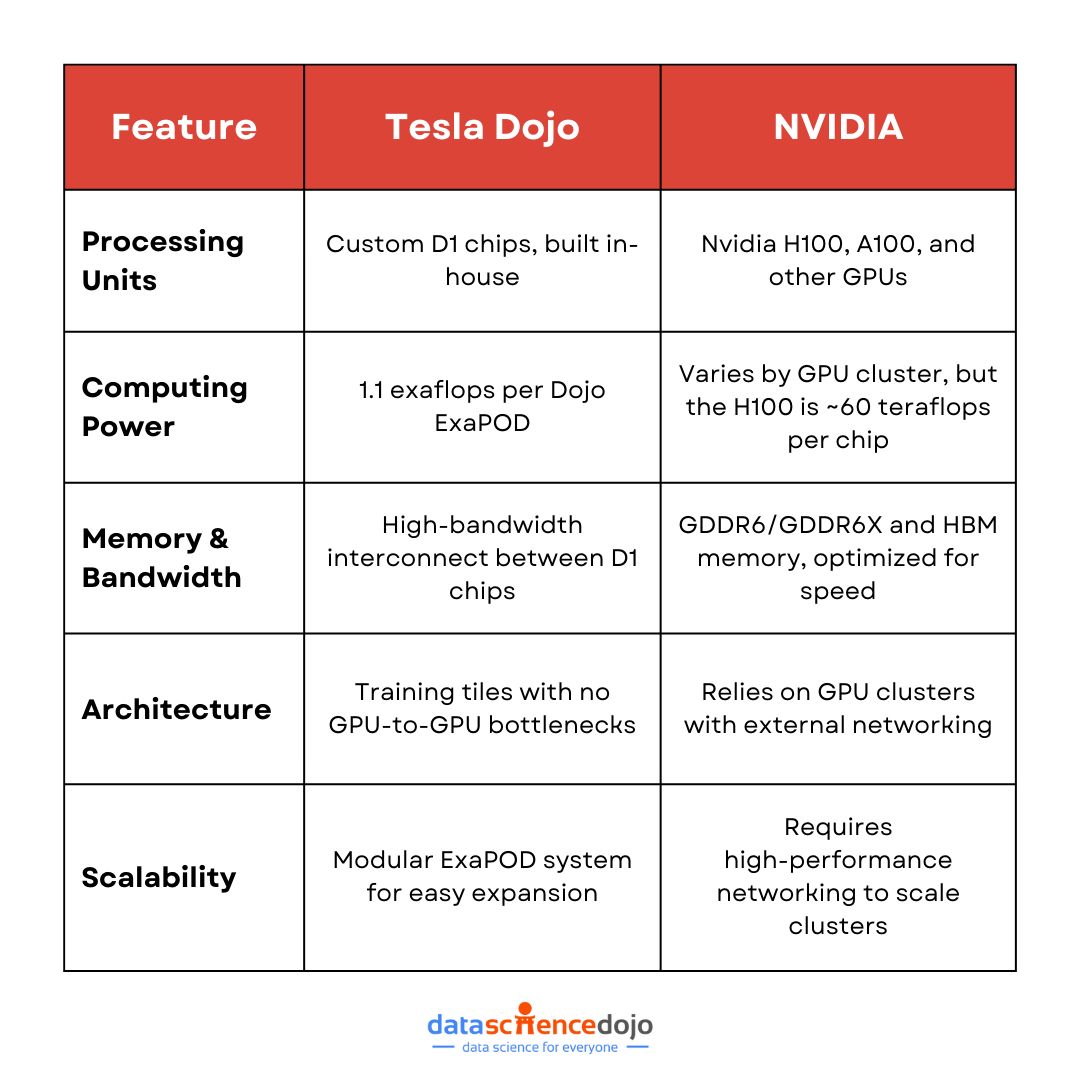
NVIDIA Corporation and Tesla, Inc. have reportedly entered into a strategic collaboration to advance AI supercomputing infrastructure—aimed at powering Tesla’s next‑generation autonomous‑driving, robotics, and large‑scale AI model training efforts. While Tesla had previously built its own in‑house system (Dojo), the shift toward leveraging Nvidia’s hardware and infrastructure marks a significant realignment in the AI arms race.
1. What the Partnership Involves
Although a formal mega‑deal announcement is still pending, several credible reports suggest the following:
-
Tesla has signalled its move away from its bespoke “Dojo” supercomputer project in favour of partnering or sourcing high‑performance computing (HPC) infrastructure from Nvidia. (AInvest)
-
Nvidia is scaling up its AI infrastructure offerings, including partnerships to build supercomputers, GPU clusters and factory‑scale AI installations—creating an ecosystem that Tesla could tap into. (NVIDIA Investor Relations)
-
The strategic move implies Tesla’s increasing reliance on external compute partners for training and inference workloads, particularly for robotics (like Optimus), vehicle autonomy and large‑model AI systems.
2. Why This Matters
-
Compute is now a strategic frontier: Training and deploying large AI models and robotics‑systems require massive GPU clusters, specialised interconnects, cooling/power infrastructure and software orchestration. Aligning with Nvidia gives Tesla access to world‑class infrastructure rather than building all of it internally.
-
Scale and cost efficiency: Building ex‑nihilo a supercomputer is extremely expensive and time‑consuming. A partner like Nvidia allows Tesla to scale faster and potentially at lower cost.
-
Future‑proofing autonomy and robotics: For Tesla to deliver full self‑driving, robotaxi networks or humanoid robots, the underlying AI compute backbone must keep pace. This partnership signals Tesla doubling down on that path.
-
Industry implication: It underlines a broader shift: hardware, software and compute‑stack leaders (like Nvidia) are becoming critical infrastructure providers in the AI era—not just component suppliers.
3. Technical & Strategic Highlights
-
Nvidia’s recently announced build‑outs (e.g., large‑scale AI systems in the U.S.) show the direction: high‑density GPU clusters, multi‑exaflop performance, energy‑efficient architectures. (NVIDIA Investor Relations)
-
Tesla’s earlier Dojo project, once aimed at creating an internal training supercomputer, now appears to be de‑emphasised in favour of external sourcing. (The Verge)
-
The compute burden for Tesla’s future (autonomy, robotics) is immense: billions of vehicle kilometers, sensor data streams, simulation workloads—thus the need for trusted, high‑throughput infrastructure.
-
From a strategic vantage: Tesla aligning with Nvidia fosters synergy: hardware + software + ecosystem. For Nvidia it means an anchor automotive/robotics customer; for Tesla it means access to best‑in‑class compute rather than reinventing it wholly.
4. Challenges & Open Questions
-
Integration and lock‑in risk: How much control does Tesla retain if it relies on Nvidia’s stack? Over‑dependence may limit Tesla’s flexibility or raise cost/competitive risks.
-
Cost and timing: Even with a partner, scaling up to the required magnitude (millions of GPUs, exaflop systems) is expensive, logistically complex, and takes time.
-
Technical alignment: Tesla’s software stack (autonomy, robotics) may have specific needs—ensuring Nvidia’s infrastructure meets those and integrates well is non‑trivial.
-
Competitive implications: Others in the robotics/autonomy space will observe carefully. If Tesla gets a compute advantage, it might widen the gap—and raise regulatory or competitive scrutiny.
-
Internal capability vs outsourcing: Tesla previously emphasised building its own compute (Dojo). Moving away from that raises questions about internal capabilities and long‑term strategy.
5. What It Means for Businesses & Developers
-
If you’re involved in AI, robotics, vehicle autonomy or high‑computing‑use‑cases: this partnership indicates that building large‑scale compute in‑house is becoming less viable—partnering with established compute providers may be the more realistic route.
-
For hardware and infrastructure providers: Systems‑level plays (chips, networking, cooling, data‑centers) are increasingly strategic; companies that were once component providers now must think “systems + stack + service”.
-
For the broader ecosystem (software, tools, MLops): The compute‑scale enabled by such partnerships will push more use‑cases (LLMs, robotics agents, simulation) into viable territory—so the software layer will matter even more.
-
If you’re in regions outside the U.S./China: Although Tesla/Nvidia primarily serve those hubs, the infrastructure ecosystem they build may trickle down to global partners—so early awareness is beneficial.
Conclusion
The reported partnership between Nvidia and Tesla on AI supercomputing marks a pivotal moment in the evolution of AI infrastructure and robotics. Tesla’s transition from building everything internally (Dojo) toward leveraging Nvidia’s compute stack highlights a pragmatic shift: scaling fast using best‑in‑class partners. While challenges remain (integration, cost, dependence), the potential payoff is huge—for Tesla’s ambitions in self‑driving and robotics, and for Nvidia’s role as a foundational compute provider in the AI era.
As this develops, it will be worth watching how this compute backbone empowers Tesla’s products, how the cost and scale dynamics play out, and how competitors respond in the race for AI infrastructure supremacy.